Aggregation: One way of speeding up query performance. Facts are summed up for selected dimensions from the original fact table. The resulting aggregate table will have fewer rows, thus making queries that can use them go faster.
Attribute: Attributes represent a single type of information in a dimension. For example, year is an attribute in the Time dimension.
Conformed Dimension: A dimension that has exactly the same meaning and content when being referred to from different fact tables.
Data Mart: Data marts have the same definition as the data warehouse (see below), but data marts have a more limited audience and/or data content.
Data Warehouse: A warehouse is a subject-oriented, integrated, time-variant and non-volatile collection of data in support of management's decision making process (as defined by Bill Inmon).
Data Warehousing: The process of designing, building, and maintaining a data warehouse system.
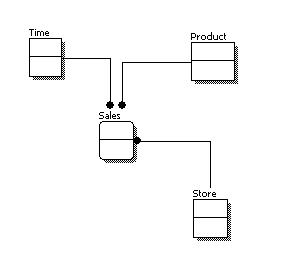
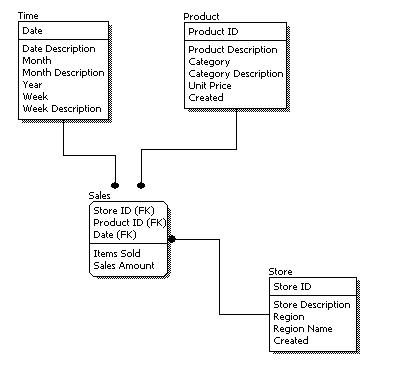
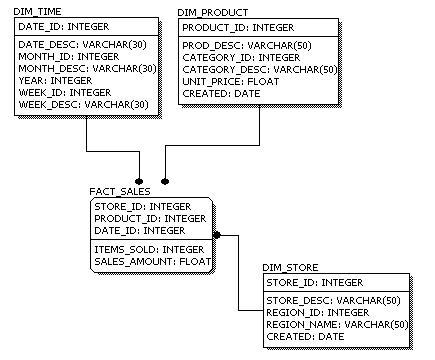
Dimension: The same category of information. For example, year, month, day, and week are all part of the Time Dimension.
Dimensional Model: A type of data modeling suited for data warehousing. In a dimensional model, there are two types of tables: dimensional tables and fact tables. Dimensional table records information on each dimension, and fact table records all the "fact", or measures.
Dimensional Table: Dimension tables store records related to this particular dimension. No facts are stored in a dimensional table.
Drill Across: Data analysis across dimensions.
Drill Down: Data analysis to a child attribute.
Drill Through: Data analysis that goes from an OLAP cube into the relational database.
Drill Up: Data analysis to a parent attribute.