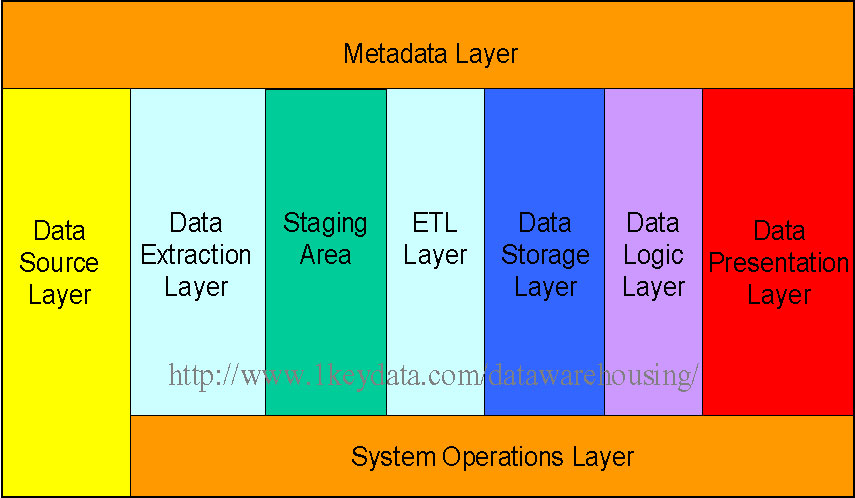
Several concepts are of particular importance to data warehousing. They are discussed in detail in this section.
Dimensional Data Model: Dimensional data model is commonly used in data warehousing systems. This section describes this modeling technique, and the two common schema types, star schema and snowflake schema.
Slowly Changing Dimension: This is a common issue facing data warehousing practioners. This section explains the problem, and describes the three ways of handling this problem with examples.
Conceptual Data Model: What is a conceptual data model, its features, and an example of this type of data model.
Logical Data Model: What is a logical data model, its features, and an example of this type of data model.
Physical Data Model: What is a physical data model, its features, and an example of this type of data model.
Conceptual, Logical, and Physical Data Model: Different levels of abstraction for a data model. This section compares and constrasts the three different types of data models.
Data Integrity: What is data integrity and how it is enforced in data warehousing.
What is OLAP: Definition of OLAP.
MOLAP, ROLAP, and HOLAP: What are these different types of OLAP technology? This section discusses how they are different from the other, and the advantages and disadvantages of each.
Bill Inmon vs. Ralph Kimball: These two data warehousing heavyweights have a different view of the role between data warehouse and data mart.
Factless Fact Table: A fact table without any fact may sound silly, but there are real life instances when a factless fact table is useful in data warehousing.
Junk Dimension: Discusses the concept of a junk dimension: When to use it and why is it useful.
Conformed Dimension: Discusses the concept of a conformed dimension: What is it and why is it important.