The snowflake schema is an extension of the star schema,
where each point of the star explodes into more points. In a star
schema, each dimension is represented by a single dimensional table,
whereas in a snowflake schema, that dimensional table is normalized into
multiple lookup tables, each representing a level in the dimensional
hierarchy.
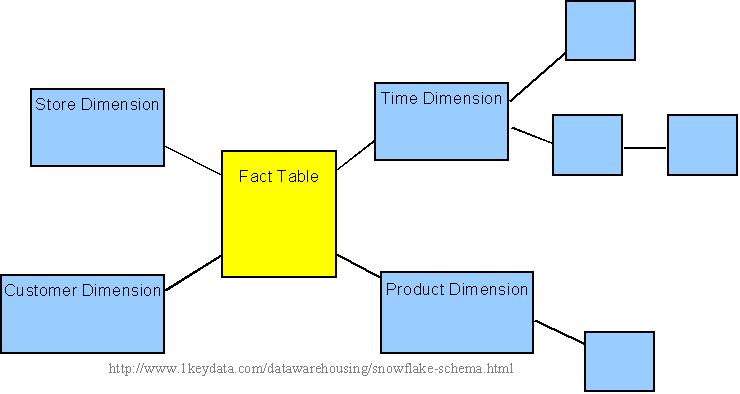 Sample snowflake schema
For example, the Time Dimension that consists of 2 different hierarchies:
Sample snowflake schema
For example, the Time Dimension that consists of 2 different hierarchies:
1. Year → Month → Day
2. Week → Day
We will have 4 lookup tables in a snowflake schema: A lookup
table for year, a lookup table for month, a lookup table for week, and a
lookup table for day. Year is connected to Month, which is then
connected to Day. Week is only connected to Day. A sample snowflake
schema illustrating the above relationships in the Time Dimension is
shown to the right.
The main advantage of the snowflake schema is the improvement in
query performance due to minimized disk storage requirements and joining
smaller lookup tables. The main disadvantage of the snowflake schema is
the additional maintenance efforts needed due to the increase number of
lookup tables.
In the star schema design, a single object (the fact table)
sits in the middle and is radially connected to other surrounding
objects (dimension lookup tables) like a star. Each dimension is
represented as a single table. The primary key in each dimension table
is related to a forieng key in the fact table.
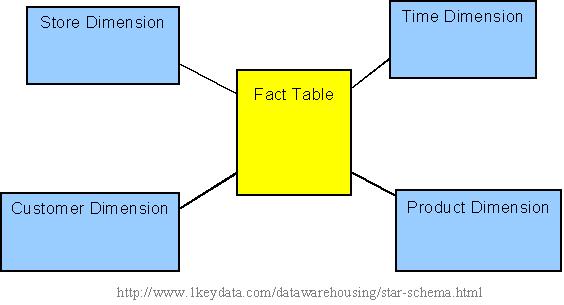
Sample star schema
 All measures in the fact table are related to all the dimensions
that fact table is related to. In other words, they all have the same
level of granularity.
A star schema can be simple or complex. A simple star consists of
one fact table; a complex star can have more than one fact table.
Let's look at an example: Assume our data warehouse keeps store
sales data, and the different dimensions are time, store, product, and
customer. In this case, the figure on the left repesents our star
schema. The lines between two tables indicate that there is a primary
key / foreign key relationship between the two tables. Note that
different dimensions are not related to one another.
All measures in the fact table are related to all the dimensions
that fact table is related to. In other words, they all have the same
level of granularity.
A star schema can be simple or complex. A simple star consists of
one fact table; a complex star can have more than one fact table.
Let's look at an example: Assume our data warehouse keeps store
sales data, and the different dimensions are time, store, product, and
customer. In this case, the figure on the left repesents our star
schema. The lines between two tables indicate that there is a primary
key / foreign key relationship between the two tables. Note that
different dimensions are not related to one another.